EtherCAT Performance Analysis
EtherCAT remains the fastest Industrial Ethernet Technology
On press conferences in November 2007, PNO/PTO published performance comparisons with EtherCAT. These have lead to some confusion, and ETG headquarters was asked to provide some clarification.
The material published by PNO/PTO was elaborated within the research project "ESANA", which is funded by the German Federal Ministry of Education and Research. Within this project, Siemens, Phoenix Contact and some other parties are looking for performance enhancement possibilities for Profinet.
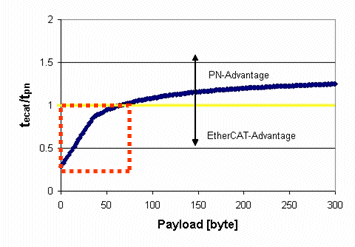
The researchers found that in typical application scenarios (line structure, 50 nodes, < 60 Bytes cyclic data per node) EtherCAT is substantially faster than the fastest Profinet version "IRT". This was illustrated with the diagram shown below (tecat/tpn, published by PNO at the press conference).
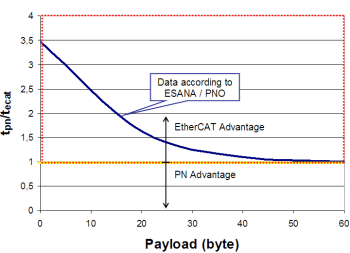
This result becomes even more obvious, if the relative cycle times (for average payload <60 Bytes per node) are compared the other way round (now: tpn/tecat). EtherCAT is substantially faster:
According to PNO, Profinet IRT is faster if the average payload per node exceeds 60 Bytes.
However, the performance comparison shown on these diagrams is at least questionable: even with very favorable assumptions for Profinet it initially was not possible to reproduce the results. EtherCAT is significantly faster than shown, since several EtherCAT features were not taken into account:
- EtherCAT can use the same bandwidth for input and output data (full-duplex usage of the frame).
- EtherCAT can send the next frame before the first one has returned (pipelining of frames).
We learned that for EtherCAT a 37,5 % overall performance penalty was used to account for unbalanced process images.
So in fact EtherCAT is substantially faster than Profinet IRT, regardless of the payload per node.
This was also shown in the conference paper "A performance analysis of EtherCAT and PROFINET IRT" published by Gunnar Prytz, ABB Corporate Research Center at the 13th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA) in Hamburg in September 2008.
For more graphs and details regarding the comparison please read the EtherCAT Performance Analysis Part 2.
Furthermore, all the Profinet calculations do not include the local stack performance in the slave devices. Unlike with EtherCAT, in a Profinet IRT slave device a communication µC (ERTEC: ARM) is taking the data from the MAC interface and makes it available to the application. With EtherCAT, this is done on the fly in hardware: the data is made available in the DPRAM or Input/Output of the EtherCAT Slave Controller without further delay.
At the same press conferences PNO/PTO showed a special application scenario (comb structure with 8 branches in which the nodes in the branch lines are only updated every 8th cycle), in which Profinet IRT allegedly exceeds EtherCATs performance. However, comparing the Profinet trunk line cycle time with EtherCATs cycle time is most misleading, since EtherCATs updates the process data eight times faster than Profinet in this special scenario - and this was not shown in the graph. The trunk line optimization is not implemented in current Profinet products anyhow.
Profinet also currently develops a new IRT version which requires new ASICs, which are under development and expected for 2009. While we cannot comment on performance of future versions before details about the technology are published, we can comment on the entire process:
- We are pleased that the PNO has chosen EtherCAT as performance benchmark and thank for the associated publicity.
- The PNO acknowledges our statement, that high-end performance with cycle times significantly below 1 ms is a relevant selection criteria for an Industrial Ethernet solution.
- The PNO analysis shows clearly, that in typical application scenarios EtherCAT is much faster than the fastest Profinet variant IRT class 3.
- We congratulate the PNO on having found a special scenario (comb structure, in which the nodes in the branch lines are not updated in each cycle), in which a future version of Profinet IRT seemingly matches or exceeds EtherCATs performance.
- This comb structure was compared with an EtherCAT line structure – and not with an even faster EtherCAT comb structure, in which the nodes in the branch lines can be updated in each cycle.
- EtherCAT is and remains the fastest Industrial Ethernet solution.
- EtherCAT does not need and will not need the complex network planing and optimization that current and future Profinet IRT variants require.